The Great Migration - How We Migrated All of Our Premium Subscriptions
- Jul 26, 2023
- 13 min read
Updated: Apr 28, 2025
Introduction
At Wix, we recently took on the challenge of migrating all of our Premium Plan Subscriptions to a new system. This was an extremely sensitive migration because we were dealing with our “bread and butter” paying customers, we needed to make sure that it would be totally transparent for these users, and that they would not lose any features that they have paid for.
In this article, I will discuss the journey of this migration, including some of the challenges, lessons learned, and how we leveraged some of the power of “Message Driven Design” in order to achieve our goals.

Photo by Barth Bailey on Unsplash
Why
Before diving into the “how”, let’s focus first on the “why”. Why did we create the new system in the first place, and why did we need to migrate all Premium Plans to this new system?
In order to understand why we created the new system, we need a brief historical overview. Wix was originally created as a tool for users to easily build beautiful websites. Like all companies, we needed a way to make money from this tool, so we introduced the Freemium business model. This allowed users to build a basic website for free. But, if they wanted more advanced features, such as connecting their website to their own domain name or accepting online payments for an e-commerce website, they needed to buy a Premium Plan.
So, we developed the required system to support the purchase flow, including the delivery of required features after purchase, subscription management - such as assigning it to a different site or canceling, etc.
As the company grew, we looked for more ways to increase revenue, besides selling Premium Plan Subscriptions. We started to sell domains, initially as a reseller and later as a domain registrar. We also became a reseller for Google mailboxes, introduced the ability for third-party developers to create plugins for the platform and sell them.
For each new revenue source, we redeveloped a similar system to support the different nuances of each new product.
As the product evolved beyond just a website builder, we started providing additional tools to help our users manage their entire business. This included CRM tools which enabled our users to keep in contact with their customers through email, chat etc. We gave our users the ability to create and send price quotes and invoices. We introduced the possibility to create virtual business phone numbers for their business, create logos and other business branding tools. We offered the ability to advertise their products on advertising platforms such as Facebook and GoogleAds.
We needed a way to monetize all of these new capabilities, and we realized that it was not scalable to redevelop the system each time. So we developed a new system that is fully customizable, and allows any business unit to configure their products and monetize them without any development required from the Premium Services team.
Now that we have this new system that readily supports the monetization of any new product, why did we decide to migrate our original Premium Plans to this new system?
From a product perspective, we were creating new features which were required by the products on the new system, as well as the original Premium Plans. This meant that we were duplicating the development effort on both systems.
From a business perspective, Wix started moving into other markets including B2B partners, agencies and enterprise customers. These users required the ability to interact with the platform via APIs, and also needed a more flexible way of tailoring the Premium Plans to suit the needs of their customers and their business requirements.
Lastly, from a technical perspective, the original Premium Plan system had lots of legacy code which was becoming difficult to maintain, and add new features to. Also, Wix infra teams created new frameworks to streamline the development process. So in order to get the full benefit of this, we needed to start using the newer frameworks and move off the older ones.
Challenges
Before getting to the point where we were ready to migrate all Premium Plans, we faced a number of challenges:
1 - Chasing our tails to achieve feature-parity
The new system lacked some capabilities that were supported in the old Premium Plans system, so we needed to add these capabilities to the new system. But while this was happening, the Premium Plans product continued to advance with new capabilities, leading to a constant game of catchup. This required every new feature to be developed first in the old system and then in the new system. We also had to challenge our product teams to consider whether these new features should be developed on the old system or wait until the new system was ready, instead of implementing them twice.
2 - API Clients
Throughout Wix, we have many applications that are consuming the Premium Plans APIs in order to know various information about a website’s Premium status. Moving to the new system meant that all these clients needed to modify their integrations with Premium Plans APIs in order to call the new system.
During the migration phase, we had Premium Plans on both systems, and we needed a way to support this scenario. We considered two possible solutions:
Have the old APIs act as a proxy to the new system, so that all clients continue to call the old APIs without even knowing that it was using the new system under the hood. Once the migration was complete, the clients could start moving to the new APIs.
Notify all clients to integrate immediately with the new APIs and have a fallback to the old APIs. Meaning they would call the new APIs first, if the plan was not yet migrated, no data would be returned, so then call the old APIs.
We chose to go with option 2 for the following reasons:
We wanted clients to integrate with the new system as early as possible to identify any gaps in the design of the new system and fix all integration points before starting migration.
Having the old APIs act as a proxy would introduce an additional “network hop” to call the new system in every call. Each external network call is a potential point of failure and adds extra latency in response times.
Without changing the old APIs, it would not be possible to benefit from all the capabilities that were introduced in the new system.
After the migration is complete, we would be able to start deprecating the old APIs without waiting for clients to move to the new APIs.
The First Stage: Lazy “On-the-Fly” Migration
Once we achieved full feature-parity, API clients were fully integrated, we were ready to start the migration. In preparation for opening the new system, the team set up a dedicated “war room” focused on monitoring the migration and immediately handling any production issues that came up.
Typically, this kind of migration is done by opening the new system only to new users, stabilizing and ironing out bugs, and only then starting to eagerly migrate existing users. However, this approach was not sufficient in our case.
We needed to avoid the complexities of having hybrid accounts (an account having some sites on the old system and some sites on the new system) because, among other reasons, it would be possible for a user to be paying for two subscriptions on the same website.
We have two flows that could cause hybrid accounts. They are:
Transfer website flow, which allows transferring a website with its Premium Plan from one account to another. So it would be possible for a website with an old plan to be transferred to an account that is on the new system, and vice versa.
Deep link to checkout page, which is a URL used mostly in email “call to action” buttons, which take a user directly to the checkout page of one of our products. This flow could allow a user on the new system to purchase an old product via the deep link, and vice versa.
In order to solve this problem we implemented a lazy “on-the-fly” migration such that if an account on the new system received an old Premium Plan either by accepting a transfer, or a deep link to the old checkout, that old Premium Plan would be immediately migrated to the new system. Similarly if an account on the old system received a new Premium Plan, the entire account would be migrated to the new system.

The first step in the migration was to create a new microservice (PlansMigrator) that is responsible for the management of the process of migrating accounts, and to be the source of truth to know which accounts have already been migrated.
Domain Events to the rescue
At Wix, the guideline is to use Event Driven architecture, emitting domain events when actions occur, and then all interested parties can asynchronously consume these events and act on them. There is a saying that “the best code is the code you never wrote”.
Using the Event Driven strategy, we were able to implement the “on-the-fly” migration without touching any of the code of the relevant flows. PlansMigrator simply consumes the appropriate events (TransferCompleted and PlanDeliveryCompleted) and then triggers the relevant migration flow if required.
The Second Stage: Eager Migration
The lazy migration only took care of these two specific flows. Of course, we needed to perform an eager migration to migrate all Premium Plans. Here, we used the divide and conquer approach. We segmented all accounts according to regions and user types, so that we could migrate smaller batches with more control. As mentioned previously, we did not want to allow for hybrid accounts. This meant that once a single plan in an account was migrated, the whole account needed to be migrated.
Here again, we made use of Domain Events, but this time for a different reason. Since it is possible for something to go wrong during the migration process, we made use of the retry mechanism that comes built in with Event Driven architecture, to ensure that eventually the entire account would be successfully migrated. In the PlanMigrator, we consumed the AccountMigrationStarted and PlanMigrationStarted events, with retry strategies to ensure that if anything fails during the migration process, it will be retried.
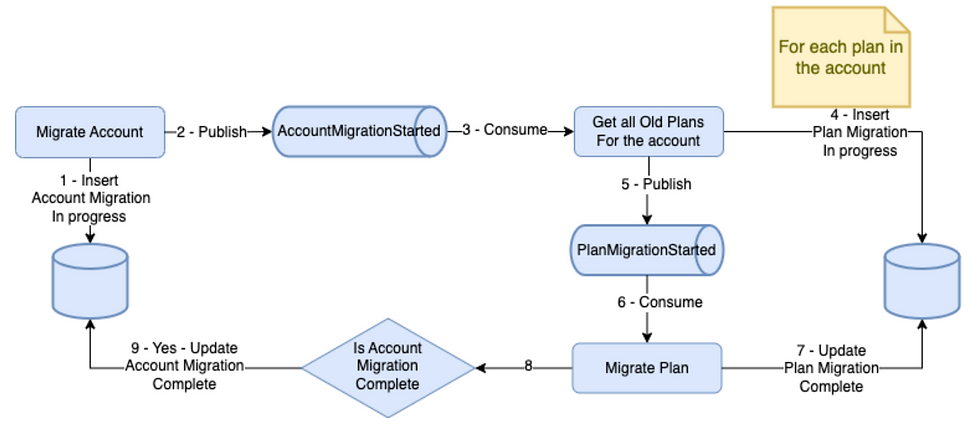
This approach requires idempotency such that if an event is consumed multiple times, the flow should be able to “pick up” from where it failed, instead of starting the process again and causing possible data duplication. The retries are used to handle unexpected failures, for example, a microservice can’t be reached, or the database is overloaded and updates fail.
We used a backoff retry strategy, retrying after 1 minute, then 1 hour, then 3 hours, etc. This type of strategy works well to handle failures that are due to unexpected system related errors. But what about failures that are due to bugs in the code? To solve this, one of my colleagues suggested adding one more retry after 30 hours. This would give us time to fix any bugs, and the failures would be retired automatically instead of requiring manual retriggering.
Disaster recovery - the code that we wrote with the hopes that it will never be used
When undertaking a migration of this nature, it is important to understand the impact of what happens if things go wrong. Do you have the ability to easily undo / rollback?
We wanted to make sure that in the case of a disaster we had a mechanism that would help us to restore things to how they were before. Due to the complexities of the data that was being migrated, this was not a simple case of undoing the change, it basically meant doing the entire migration logic in reverse.
We implemented this, but it came with the same complexities as the migration itself, and therefore did not really guarantee the ability to restore to the previous state. Fortunately, we did not need it.
Monitoring and Alerts
In order to know the status of the migrations and to be able to troubleshoot, we made sure to log enough data during the entire migration process. These logs were used to create an informative dashboard which gave us an overview and allowed for easy monitoring of what was happening during the migration, including migration rates, error rates, db lags, etc. Using this dashboard, we were able to identify and act, as soon as possible, on any issues that occurred.
We also created many BI driven alerts, which check for data inconsistencies, and give us daily reports of any inconsistencies that need to be fixed.

Lessons Learned
Of course the process did not always go as smoothly as planned, and we had many bumps along the way. I will share some of the issues that we experienced, and the lessons learned:
When it comes to database connections, sometimes less is more: We had a case where we started a migration, this triggered many events for all the newly created plans. One of our consumers autoscaled in order to handle the load. This consumer was configured to have a large number of database connections per instance, so as it autoscaled, it created more and more database connections, eventually choking the entire database cluster and bringing down other applications at the same time. When we realized this was happening, we immediately stopped the migration, giving the database time to recover. The fix was to reduce the number of database connections in the pool and also reduce the maximum number of instances that autoscaling would add.
Be cautious of the “read your own writes” issue: The “read your own writes” is a well known problem that occurs when you write to the database and then immediately try to read that data. However, the read is done with a readonly connection which reads from a replica that is still not updated, resulting in an inconsistent read. During the migration, we experienced a significant increase in this type of problem, where consumers in a different microservice would get stale reads because they processed an event before the read replica was fully updated. This happens because of increased load on the database, causing replication lags. To avoid this problem, it’s best to include all necessary data in the event itself, so that the consumer doesn’t have to perform a read at all. Another option that works in some cases is to force consistent reads by reading from the master. This has some performance considerations and is not usually recommended.
Consumer lags: During migration, many events are triggered. If the consumers cannot process the messages quickly enough, queues start to build up, causing delays in the handling of actual new messages which are not related to the migration. One way to solve this, is to control the migration throughput, limiting the rate so that these consumer lags are kept to a minimum. Of course it also helps to configure consumers to autoscaling under load, so that they will add more instances to handle the increased traffic.
Performance issues are accelerated due to unnatural increase in load: Usually performance bottlenecks are something that slowly deteriorate with time as the size of the data grows. But when migrating huge amounts of data in a short space of time, these inefficiencies show up much quicker, and need to be attended to quickly. One of the cases that we found during our migration was related to incorrect database indexes, which lead to slow running queries. We had to pause the migration for a few days in order to consult with the DBA team and reindex the database with the correct indexes.
Communication of the rollout plan with all API clients: As mentioned previously, we chose to go with the requirement for our clients integrating with the new APIs, with a fallback to the old APIs. Unfortunately, this communication missed some teams, who only found out about the required changes when the migration was already underway, and the old APIs started to not return the expected data. To address this issue, it required prompt action by our team, working together with the affected teams. Retrospectively, this could have been avoided by choosing the option that ensured that the existing APIs continued to work, with some monitoring to know who is still calling these APIs, so that the changes would be communicated earlier instead of returning unexpected results.
Staggering size of the accounts: We realized early on in the process that the size of accounts needs to be randomized, and it is not good to have all the bigger accounts at the beginning of the batch. In one batch, this requirement was missed, leading to many issues. The root of the problem was that all these larger accounts started migrating in a short period of time, creating an unusually high load of Plan Migration Started events. This load basically put too much pressure on many resources including the database, and the Plan Migrator. An important lesson that we learned from this incident was the necessity of a “killer switch”. We realized that something was not right and stopped the batch. However, the events were already in the queue, and we had no way to stop those events from being processed or drain the queue. A “killer switch” would have allowed us to drain the queue of all these events, without causing further damage.
Race conditions: We experienced two types of race conditions, which were not necessarily related to the migration, but more a result of the fact that the new system is heavily based on events, and race conditions are one of the downsides of Event Driven Architecture.
The first race condition is when you produce one event, which is consumed by multiple consumers that might be dependent on each other. For example ConsumerA and ConsumerB both consume the same event, but ConsumerB is dependent on ConsumerA completing.

Solving this is a challenge. Ideally ConsumerA should produce a new event when it is complete, and ConsumerB should instead listen to this new event. But when integrating into an existing architecture, this type of change is not always possible. An alternative workaround is for ConsumerB to be able to “recognize” that ConsumerA is still busy and throw an exception that will cause a retry, in the hope that by the time ConsumerB handles the retry, ConsumerA will have completed.
The second race condition is when you produce two events that should be handled in the same order, but they are consumed out of order. As a result, the effects of the second event are lost, because the first event is consumed after the second.

Solving this problem is also a challenge. One solution is to make use of the underlying messaging system to ensure that messages are consumed in the correct order. For example, at Wix we use Kafka, which allows production with a unique partition key and ensures to the best of its ability that messages with the same partition key are consumed in the order they were produced.
Another option is to use a version in the event, so that the consumer is able to identify when messages are consumed out of order.
But this solution requires that the consumer has some state to know the version of the consumed events. The last option is to use more “atomic” events instead of producing two events, combining them into one event that can be handled without worrying about ordering.
Conclusion
Migrating premium plan subscriptions to a new system was a significant undertaking that required careful planning and execution because we were dealing with our paying customers and needed to provide a seamless transition without any loss of features. This article has highlighted some of the challenges we faced during the preparation and migration process.
We learned about the importance of “Message Driven Design” and how it helped to achieve two very important goals. Firstly, consuming existing domain events in order to trigger lazy migration without modifying the existing flows, and secondly, leveraging the power of retry mechanisms in order to ensure eventual consistency of a potentially long running process. We also discussed some of the unexpected obstacles that were encountered, such as DB overload, “read your own writes” issues, race conditions, consumer lags and general performance degradation caused by very fast increase in data size.
We saw the importance of monitoring dashboards and BI alerts in order to identify these issues and deal with them as quickly as possible. Overall, the experience has taught us valuable lessons that will help us plan and execute similar migrations more efficiently and effectively in the future.

This post was written by Gavin Rifkind
More of Wix Engineering's updates and insights:
Join our Telegram channel
Visit us on GitHub
Subscribe to our YouTube channel



Comments