Storage Lifecycle: How We Cut Cost on 55% of Our Storage Without Deleting a Single File
- Wix Engineering

- Jan 10, 2021
- 7 min read
Updated: Aug 17, 2021

Photo by CHUTTERSNAP on Unsplash
When we talk about the cost of the Cloud, storage is not the first component that comes to mind. Compared to computing power, networking, databases - things that most applications will use - storage is relatively cheap. It takes some time for a system to grow into a scale that will make you think about your storage costs.
At Wix, we store Petabytes of data. Storage costs might be cheaper than computing power, but it is far from being plainly cheap. Moreover, while computing power is derived from current usage, storage is forever. So for every new video, photo and document a user uploads, even if it’s never used or watched, not even once, Wix will have to pay for - forever. And that is inefficient to say the least.

To be more finance-friendly, we initiated a Storage lifecycle management project.
We understood that not all files should be treated equally, and built a system that monitors file demand and classifies files according to different storage classes, thus significantly cutting on costs.
What does it do and what it all means? Let's dive deep into it!
The Long tail
When users that build their sites with Wix they often upload a multitude of files - pictures, videos, documents, basically any file they want to make available on their site. These files are stored, and then accessed when the user’s site gets a visitor. It can be a visitor playing a video, downloading a restaurant menu or just opening the home page and loading the background image. Most of these operations will issue HTTP requests that will eventually be served from our storage.
The long tail pattern means that each file that a user uploads to Wix will see its best days at the beginning of its lifetime. So, if I upload an image to my Wix site today, it will probably be accessed the most in the coming month or two. From there, it will see a decrease in hits until it will receive none to very few once in a while. Of course, that is an average file. There are a lot of other files that will last for years and will be accessed a lot - we are not targeting those.
Cloud Storage classes

AWS and GCP both offer different storage options. From the Standard class that costs the most and offers the best speed and availability, to lower classes that offer cheaper storage with some limitations.
Each storage class has a different set of limitations. Here are some common limitations for the big cloud providers:
Minimum duration - defines the minimum amount of time a file should stay in a storage class before it can be moved. Getting a file out of that storage class before it reaches its minimum storage duration will trigger an early deletion fee to be charged.
Data retrieval Fee - fetching files from cheaper classes has a higher data retrieval fee.

So with great savings comes great responsibility.
We want our solution to move files to cheaper classes to save money, but we really want to make sure we’re doing the right thing and not moving the file back - at least not soon. Of course, we will always have files that move upstream - that’s ok, since we can’t predict future usage with a 100% guarantee. But we do want to keep those cases to a minimum.
In this case the solution is to use specific storage classes with specific cloud providers.
Google (GCS) => Standard, Nearline, Coldline
AWS (S3) => Standard, Standard-IA
We limit the number of options because we have to use storage classes that will save us money but will still allow us to:
Serve files without any latency impact (same latency SLA as standard).
Replicate to multiple AZ’s, and not a single one, to avoid data loss in case of a disaster.
What do we do?
In order to decide on a per-object basis what storage class it belongs to, we have to know when was the last time a user requested it.
In Wix, we store our files with multiple cloud storage providers. Two of the main ones are Google and Amazon. Google cloud storage, aka GCS (Google), and S3 (Amazon). Both cloud providers offer multiple layers of storage at different prices.
What is more important, with both solutions we have an ability to get Access logs for the storage files. So we set our cloud buckets to write access logs to a specific place so we can later process them.
Our solution is divided into two parts. Classification and Migration, which both run on a daily basis. The computing power is backed by Google Dataflow, which is Google’s managed, hosted solution for distributed data processing, and the Database is backed by Google Datastore.
Classification

In the classification stage, we ingest all of the access logs from the day before, finding the last access time for each file and writing it to our Database.
Example log line from GCS:
"Time_micros","c_ip","c_ip_type","c_ip_region","cs_method","cs_uri","sc_status","cs_bytes","sc_bytes","time_taken_micros","cs_host","cs_referer","cs_user_agent","s_request_id","cs_operation","cs_bucket","cs_object"
"1601866801331450","34.***.229.81","1","","GET","/storage/v1/b/<bucket name>/o/<filename.jpg>?alt=json&prettyPrint=false&projection=full","200","0","2079","16000","storage.googleapis.com","","gcloud-golang-storage/20200911,gzip(gfe)","***","storage.objects.get","<bucket name>","<filename.jpg>"
As you can see in the example above, each line of the log has the bucket name, file name (path in bucket) and time it was last accessed. We do it for all buckets and all cloud providers, configured in the system.
After all log files are ingested, we combine all the parsed data into a key value-structure where each key is a unique identifier for a file and the value is the max(access time) for each file. Because files can be accessed multiple times, we want to make sure that we have a single timestamp for each file which is also the latest.
Next step is we take all of this data and write it to our DB. If we already have a particular file on record, the last accessed timestamp is updated.
Objects Migration stage
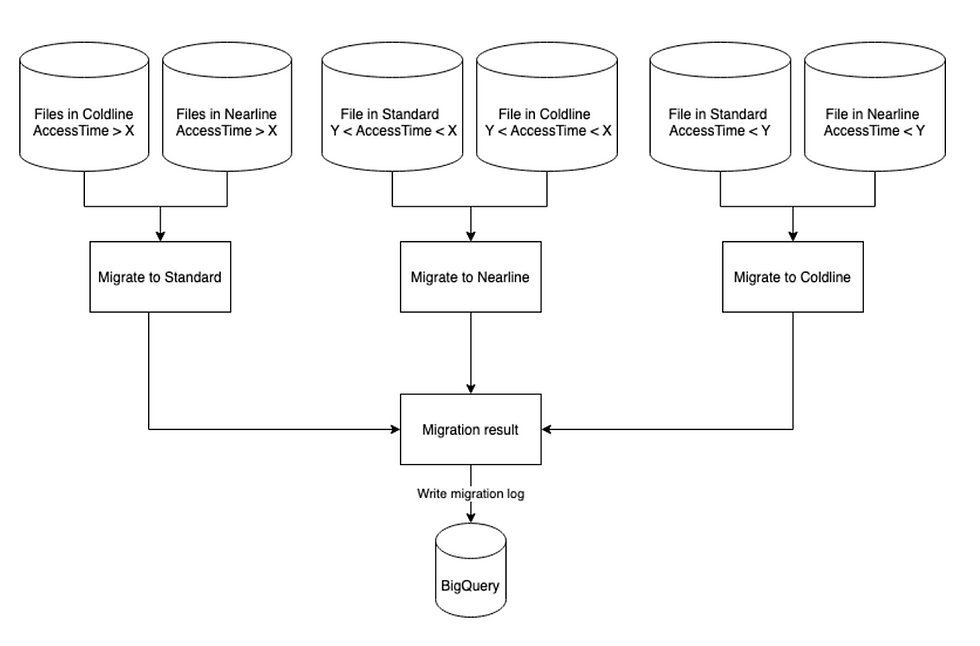
The migration stage is where the heavy lifting is done. In this stage we go over our Database and query for all the files that their last access timestamp doesn’t match their storage class.
Now, as you remember, when we find a log record for a file that already exists in the database, we only update the timestamp. If we didn’t encounter a file, the timestamp won’t be changed. Because we also have the storage class for each file in the database, this will cause discrepancies in future runs.
For example, a file was uploaded on date X and entered into the database with date X and storage class “Standard”. After 90 days of inactivity, the last access timestamp is still X, but today is already X+90. This situation is the trigger for a migration.
To do the migration we decide on time ranges and pair them to storage classes. This is done after a long investigation of our storage usage, and might differ between systems.
With Google, we’ve got 3 storage classes (that’s a bit different for AWS): Standard, Nearline and Coldline. Standard is the expensive one, Nearline is a bit cheaper and Coldline the cheapest.
Note: there are more classes that are even cheaper, but here we’re only talking about classes that can still serve files when needed with good latency.
So we decided that:
A file was served in the last 90 days -> Standard
A file was last served between 90 to 120 days -> Nearline
A file was not served in the last 120 days -> Coldline
With that in mind, the migrator can query the Datastore for all the files that need to be migrated and do its job.
Because with the Datastore we pay per each operation, we want to save as much reads as we possibly can. So we only query files that need to be migrated. We do it by querying all records between a date range that have a different storage class than they should. This way we know in advance for each query which storage class should be assigned to all of the returned records.
For example, to get all files that need to be migrated back to Standard, we’ll query:
From Nearline:
Last Access time < 90 days
Storage class == Nearline
From Coldline:
Last Access time < 90 days
Storage class == Coldline
Note: “But why is that not just 1 query?”, you may ask. Why not do “OR” or “!=” ? That is because Datastore doesn’t support these operators.
How much did we save (so far)?
For now, we are using this system on media files in Wix - Images and Videos. In an effort to give the best user experience, we run on both cloud platforms (AWS and Google) and have them both actively monitored so that in an event of a failure we could move traffic between them without any user impact.

For this to be possible we copy all of our media files to both platforms.
This way, the server that is serving the data is as close as possible to the data itself. Which also means that for every file we move to a lower storage class, we double the cost savings :)
After running the solution on all of our media files, we managed to move about 55% of all the media files from a standard storage class to Standard-AI/Coldline/Nearline.
As mentioned above, we store Petabytes of data. Let’s just say, the cost savings are HUGE!

(One of our buckets in S3)
We continue to run this solution on a daily basis, so every day there are a lot of new files uploaded by users, while at the end of the day, a lot of other files are moving from standard storage class to a “colder” one.

This keeps our “hot” storage relatively static in size while our “colder” one grows. In terms of cost, our daily cost increase rate is now 45% slower!
Operation cost
Of course, running this whole operation has it’s cost too. You have the compute instances, database and the API costs for all of the cloud providers. But calculating those is a bit more difficult and depends on the use cases.
Moving files higher in the chain of classes has some penalty costs, and depending on the amount of files migrated daily, the compute power varies.
Taking all of this into account, at the end of the day it is up to you to decide if savings in utilizing cheaper storage classes will cover your operational costs. This is, in my experience, something that should be evaluated over time.
Summary

Storage Is Forever... (Photo by Sabrinna Ringquist on Unsplash)
After more than a decade of storing data, we realized that storage is FOREVER. Every byte we ingest will affect our monthly bill for good. Today, when we need to design new systems that consume a lot of storage space, we keep this approach in mind. We design the system to be storage-cost-efficient in advance, utilizing everything the cloud has to offer us in this regard.
Just like you optimize your code making it more efficient, resilient, and fast, you have to think about optimizing your storage. Even if data is your business and you can’t avoid the growing storage, there are ways to manage it and get to significant cost savings. And nowadays, when it’s all in the cloud, hiding behind nice APIs, it’s not even that hard :)

This post was written by Idan Yael
For more engineering updates and insights:
Join our Telegram channel
Visit us on GitHub
Subscribe to our YouTube channel


