SageMaker Batch Transform Unleashed: My Journey at Wix to Achieve Scalable ML
- Wix Engineering

- Apr 17, 2024
- 9 min read
Updated: Apr 28, 2025
Insights and Lessons Learned from Wix's Implementation of AWS SageMaker Batch Transform for Streamlined ML Deployment at scale.

Photo by Lajos Szabo on Unsplash
Introduction
Hello, fellow data enthusiasts! Today, I'm excited to share a behind-the-scenes look at a project we did at Wix — we're implementing AWS SageMaker Batch Transform to run machine learning models at scale.
As I started working with SageMaker Batch Transform, I realized that practical documentation and examples were lacking, particularly in building an end-to-end pipeline for processing large-scale data that incorporates Sagemaker Batch Transform. Some applications were notably absent, such as: handling errors, dealing with Parquet files, or performance optimization. Motivated by this gap, I decided to document my experiences, for the benefit of the community.
In this blog post you’re expected to see a detailed walkthrough of implementing Batch Transform within Wix's infrastructure, along with what I call Insight Bites, hopefully teaching you something new, whether you’re new to ML or a seasoned pro. Let's dive in!
About Wix
Wix is a web development platform that allows users to create websites, without extensive coding skills, utilizing a user-friendly drag-and-drop interface and customizable templates. It offers a range of tools and features for both individuals and businesses. Every day more than 200 machine learning models run at Wix, performing tasks like classification, fraud detection, text embeddings, and more.
About Sagemaker
Putting machine learning models into production is complicated. AWS SageMaker is a machine learning service that aims to simplify this process. It enables developers and data scientists to build, train, and deploy machine learning models in the cloud.
Once you build and train a model, you want to invoke it with some input data. To do so, Sagemaker provides us with 4 options, that differ from each other in their limitations and cost models:
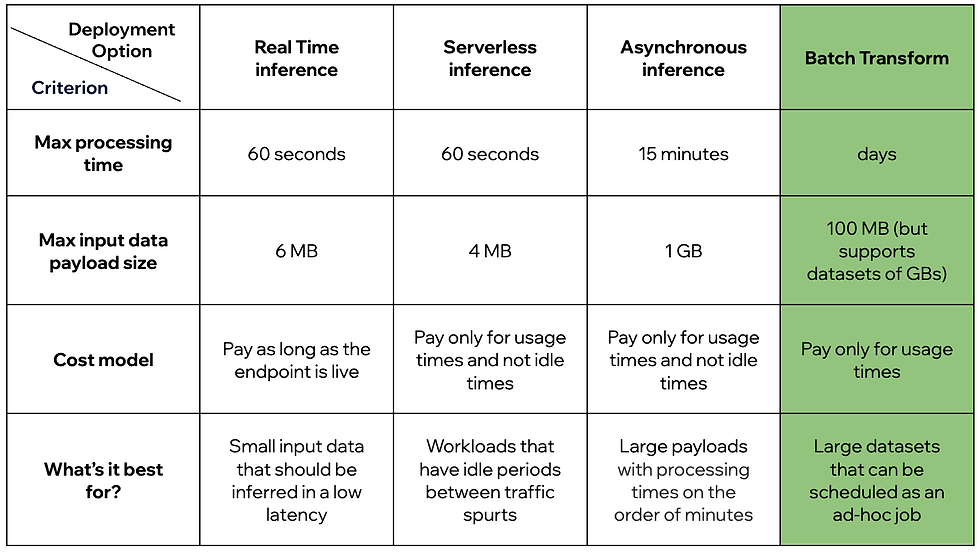
Why did we choose Batch Transform?
While we have both online and offline use cases at Wix, for the offline prediction scenario, we opted for Batch Transform. This decision aligns with our requirements as we prioritize scalability and flexibility over low latency, which are crucial for our offline inferences. Batch Transform empowers us to process large datasets efficiently and fine-tune various parameters to optimize both cost and performance.
Some particulars regarding our ecosystem:
Data is saved as Parquet files
We use Airflow as an orchestrator for our data pipelines
We incorporate Spark in our data pipelines
.
High level look on the flow:
Every time a batch prediction job of a model is triggered or scheduled, an Airflow DAG is triggered as well. The primary task in this Airflow pipeline is the Batch Transform task (trigger_model in the below screenshot). However, both preceding and following this task, other essential operations take place.
Let’s take a high level look at the Airflow pipeline to understand the flow:

Input Data Preparation:
As mentioned above, our data is saved in Parquet files. Unfortunately, Parquet type isn’t supported natively by Batch Transform, meaning we can’t simply point the Batch Transform job to parquet files and expect it to work. Therefore our goal is to convert the parquet data files to one of the supported types. We chose JSONLines as the chosen type. So how is this Parquet-JSONLines conversion done?
First, we load the parquet files into a Spark dataframe.
Then, we divide the dataframe into partitions, convert each one of them to a JSONLines format. For example, the following dataframe:
Will be converted to the following JSONLines file:

Row 1
{“site_id”: 1629c-8785“”, “is_premium”: True, “language”: “EN”, “app_ids”:{"Widget": ["4276f-ba62"], "MultiSection": [], "Master": ["14f81-5215", "4abcb-fbdb"]}, “site_date_created”: “2023-08-26”}
Row 2
{“site_id”: 13ee3-ecb9“”, “is_premium”: False, “language”: “NL”, “app_ids”:{"Widget": [], "MultiSection": ["14995-f076"], "Master": ["bbe4a-31f5", "14ff1-5215"]}, “site_date_created”: “2021-01-12”}3. Upload each JSONLines partition as a separate file to S3.
At the end of this step we have a path within S3 where our input files are stored.
--> Insight Bites
Why did we opt for JSONLines over JSON?
In essence, any format that supports splitting is preferable.
Our Batch Transform job receives a list of input files, each containing multiple rows of varying sizes. When a file is splittable, SageMaker divides it into batches of rows, with each batch limited by the defined payload size, and processes them individually. However, if a file cannot be split, it is processed as a whole, necessitating that we set the payload size to accommodate the largest input file. This reduces our flexibility in parameter optimization, requiring us to choose a larger payload size than necessary.Consequently, this impacts the number of concurrent transforms, prolonging job duration. For instance, JSON is a format that cannot be split, leading to suboptimal configuration for the Batch Transform job (more about this topic in the “Model Execution” section).
Let’s review an example: three input files with these sizes in MBs - [12, 45, 28]. Each contains multiple rows, let’s say the largest row weighs 6MB. If these files will be in a JSONLines format, which is splittable, we will be able to set the parameter max_payload_size to 6 and as a result max_concurrent_transforms will be 100/6 = 16. If these files will be in a JSON format, which is not splittable, we will need to set max_payload_size to 45 and as a result max_concurrent_transforms will be 100/45 = 2. We prefer more parallelism and therefore prefer the JSONLines option.
Model Execution:
At this stage we’ll be running a Sagemaker Batch Transform job Using the Python SDK provided by Sagemaker.
I'd like to emphasize the importance of two parameters that significantly impact the performance of the Batch Transform job: max_payload and max_concurrent_transforms. Properly tuning these parameters can greatly enhance the job's speed. Many decisions I've made throughout the process, for example the above mentioned "Insight Bite", have been aimed at optimizing these parameters.
The main thing to remember is that there is a tradeoff between them:
bigger max_payload ⇒ smaller max_concurrent_transforms.
That’s due to the given condition: bigger max_payload * smaller max_concurrent_transforms <= 100.
On one hand we want to set max_payload to be as big as possible so it will be able to handle big payloads. But on the other hand, we want to increase max_concurrent_transforms to achieve maximum parallelism.
The best approach to determining optimal values is by understanding your data. By knowing the average and maximum sizes of your payloads you’ll be able to set a value for max_payload and derive from it your parallelism. The default value AWS sets is 6MB, but I personally use 8MB as a default value.
This is the Batch Transform call that’s done by the Python SDK:
from sagemaker.transformer import Transformer
tf = Transformer(
model_name=model_name_for_sagemaker,
tags=tags,
instance_count=num_instances,
instance_type=instance_type,
output_path=f"s3://{BUCKET}/{JOB_DIR}/{OUTPUT_DATA_DIR}/",
sagemaker_session=sagemaker_session,
strategy="MultiRecord",
accept="application/jsonlines",
assemble_with="Line",
max_concurrent_transforms=max_concurrent_transforms,
max_payload=max_payload_size,
env=env_vars
)
tf.transform(
job_name=job_name,
data=f"s3://{BUCKET}/
{JOB_DIR}/{MANIFEST_DIR}/
{MANIFEST_FILE_NAME}",
data_type="ManifestFile",
content_type="application/jsonlines",
split_type="Line",
wait=False,
model_client_config={"InvocationsTimeoutInSeconds": 3600}
)--> Insight Bites
Why did we opt for “ManifestFile” data_type and not “S3”?
Manifest file allows for more granular control over selecting specific files, from a directory, as opposed to choosing the entire directory in the “S3” option. This comes handy when we want to run only some files, for example: failed ones.
--> Insight Bites
Invocation timeout
Increase the invocation timeout by setting the InvocationsTimeoutInSeconds parameter, default value is 600. For example: model_client_config={"InvocationsTimeoutInSeconds": 3600}
After the Batch Transform was triggered successfully, it will appear in the AWS Sagemaker UI:

Now all we have to do is wait for it to finish, and hopefully succeed:

While the job is running, we’re using the Airflow Sagemaker transformer sensor (wait_model_run_to_finish in the Airflow graph above), which constantly polls the job status until it returns “Success” or “Failure”.
from airflow.providers.amazon.aws.sensors.sagemaker
import SageMakerTransformSensor
wait_model_run_to_finish = SageMakerTransformSensor(
task_id='wait_model_run_to_finish',
aws_conn_id=AWS_CONN_ID,
job_name=JOB_NAME, mode="reschedule",
retry_delay=timedelta(minutes=3),
timeout=60 * 60 * 8
)Retry Mechanism and Errors Handling:
First, let’s understand what an error is. Let’s say we have 1,000 input files; we expect to have 1,000 output files at the end of the Batch Transform run, one output file for every input file.
If a batch transform job succeeds, it means all input files were processed successfully. On the other hand, if the job fails to process one or more input files, SageMaker marks the entire job as failed.

So, returning to our example, if you have 1,000 input files and one of them fails to be processed, the entire job will be marked as Failed.
This is an error.
An input file can fail to be processed for various reasons - for example, if it has a corrupted row, or if its size is bigger than the max_payload of the job.
--> Insight Bites
Inconsistent instance initialization
While some instances may initialize successfully, others may encounter issues.
By default, SageMaker copies the model to each CPU of the instance, enabling parallel inference and maximizing resource utilization.
However, heavy models may lead to errors. Consider selecting an instance with fewer CPUs to reduce the number of model copies, especially if encountering borderline cases where some instances initialize successfully. You can identify this issue if there are more instance logs than data logs for the Batch Transform job in CloudWatch (the number should be equal - for each instance log, there should be a corresponding data log with the same instance ID).
--> Insight Bites
Partial processing of input files
If only a portion of the input files are successfully processed while others fail (and not because the max_payload_size isn’t big enough), it could indicate a memory limitation. In such cases, consider selecting an instance with higher memory capacity to mitigate potential out-of-memory issues during processing.
So to summarize quickly - if a batch transform job fails it means that one (or more) input files failed, and that means that one (or more) rows in this input file failed. The way to solve it is either by changing the configuration or by isolating the problematic row, so it and only it will fail.
By default, SageMaker doesn’t have a retry mechanism or failure handling, which forced me to create one. Ultimately, we’ll want to run the job again and hope that it succeeds or at least that the overall success rate of the job is as high as possible.
But before we rerun the batch transform job, we’re taking a few steps in light of what we described above:
Identify the failed files - check how many input files were processed successfully and how many failed, by looking at the S3 path of the input and output we defined in the job.
Isolate the problematic row - split the failed files into single-row files. This means that if an input file that failed contains 100 rows, after the split there will be 100 files, each containing 1 row. When we rerun the process with new files, if a file fails, we can be certain that only the problematic rows failed, and nothing else.
Change the job configuration - set the maximum payload size parameter to the maximum value possible, which is 100MB. It’s not optimal, as mentioned in the “Model Execution” section, but it will ensure that we’re maximizing the Batch Transform payload capabilities.
Now we rerun the job with the new configuration on the new single-row files.
What have we achieved by changing the configuration? We’ve maximized the success rate of the job; now, only rows that absolutely can’t be processed–whether it’s because they are corrupted, bigger than the maximum payload of 100MB, or for any other reason–will fail. The rest of the rows will be processed successfully.
Parsing the Model’s Output:
At this stage we’re merging the output files with their corresponding input files to a Spark dataframe. It's fairly straightforward to merge the input and output because:
File names match - for the input file “input_data_1.jsonl” the matching output file will be the same but with “.out” suffix, meaning “input_data_1.jsonl.out”.
Rows are in the same order - the sequence of rows in both the input and output files remains unchanged.
Finally, after merging all the files into a dataframe, we’re storing it as parquet files.
--> Insight Bites
Why did we opt for joining the output to the input ourselves instead of simply using “join_source=Input”?
Because of how this affects the parameter max_payload_size.
Generally, this parameter must be equal or greater than a single input record. But, when we use the join configuration for the output results (transormed results + Input record), meaning set “join_source=Input”, we should configure the size of the max_payload_size to be much larger than the actual record size to allow the joined results to be written to the memory buffer.
Actually the best practice is to set the max_payload_size parameter a size of up to 2x the actual size of the Input file when "Join" configuration feature is used in your batch transform job.
We want to keep max_payload_size as small as possible, in order to set max_concurrent_transforms as big as possible - between these 2 parameters there is a direct relation and one comes at the expense of the other: max_payload_size * max_concurrent_transforms <= 100Thus, we chose join_source=None, in order to set a smaller value for max_payload_size and keep our Batch Transform job as optimal as it can be.
Conclusion
In summary, we've navigated the deployment of AWS SageMaker Batch Transform at scale within Wix's infrastructure, integrating it seamlessly into our Airflow pipeline alongside Spark.
Our journey encompassed essential tasks such as data preparation, model execution, and output parsing, highlighting the following key insights:
Prioritizing JSONLines input data format over JSON format
Optimizing Batch Transform job performance by balancing payload size and concurrency.
Prioritizing ManifestFile “data_ type” over S3
Tradeoff between using “join_source=Input” and “join_source=None”
Retry mechanism
Error handling - invocation timeout, inconsistent instance initialization, and partial processing of input files
As we continue to refine our processes, we welcome any insights and ideas that contribute to our collective growth and success in the realm of machine learning deployment.
Thank you for reading!

This post was written by Elad Yaniv
More of Wix Engineering's updates and insights:
Join our Telegram channel
Visit us on GitHub
Subscribe to our YouTube channel


